
When HHVM Doesn't Work Quite Right
Despite generally resisting the hype train, in the past year I’ve jumped onto two relatively new Facebook projects. ReactJS and HHVM. I’m a huge proponent of both and enjoy working with them immensely. Except when I don’t.
Around 3 months ago I chose HHVM for a new project and was initially very excited by the static analysis tools, built in profiling and great performance. Despite many great examples of HHVM deployments, shortly after deploying to production we started hitting OOMs pretty frequently:
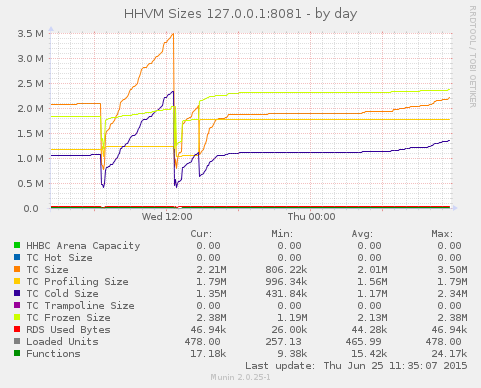
With some heap profiling I first located a leak in mongofill-hhvm, and removed our one instance of create_function (known to leak memory) but still experienced poor reliability post-fix. By now, we’d jumped onto the nightly builds as some leaks were fixed. At this point, we started hitting segfaults and our HHVM binary occasionally refusing to accept fastcgi requests.
diffing heap dumps from jemalloc:
-------------------- /tmp/heaps/.9371.29.u29.heap => /tmp/heaps/.9371.30.u30.heap --------------------
Total: 2639139 B
4740389 179.6% 179.6% 4740389 179.6% bson_realloc
0 0.0% 179.6% 2639139 100.0% HPHP::AsyncFuncImpl::ThreadFunc
0 0.0% 179.6% -3317645 -125.7% HPHP::ElemSlow
0 0.0% 179.6% 1422744 53.9% HPHP::ExecutionContext::executeFunctions
0 0.0% 179.6% -678506 -25.7% HPHP::ExecutionContext::invokeFunc
-------------------- /tmp/heaps/.9371.30.u30.heap => /tmp/heaps/.9371.31.u31.heap --------------------
Total: 4598623 B
4598623 100.0% 100.0% 4598623 100.0% bson_realloc
0 0.0% 100.0% 4598623 100.0% HPHP::AsyncFuncImpl::ThreadFunc
0 0.0% 100.0% 3317645 72.1% HPHP::ElemSlow
0 0.0% 100.0% 7916269 172.1% HPHP::ExecutionContext::executeFunctions
0 0.0% 100.0% 7916269 172.1% HPHP::ExecutionContext::invokeFunc
-------------------- /tmp/heaps/.9371.31.u31.heap => /tmp/heaps/.9371.32.u32.heap --------------------
Total: 5829623 B
3317645 56.9% 56.9% 3317645 56.9% HPHP::MemoryManager::newSlab
2511977 43.1% 100.0% 2511977 43.1% bson_realloc
0 0.0% 100.0% 5829623 100.0% HPHP::AsyncFuncImpl::ThreadFunc
0 0.0% 100.0% 2511977 43.1% HPHP::ExecutionContext::executeFunctions
0 0.0% 100.0% 2511977 43.1% HPHP::ExecutionContext::invokeFunc
-------------------- /tmp/heaps/.9371.32.u32.heap => /tmp/heaps/.9371.33.u33.heap --------------------
Total: -947455 B
2370189 -250.2% -250.2% 2370189 -250.2% bson_realloc
0 -0.0% -250.2% -947455 100.0% HPHP::AsyncFuncImpl::ThreadFunc
0 -0.0% -250.2% -3317645 350.2% HPHP::ElemSlow
0 -0.0% -250.2% -947455 100.0% HPHP::ExecutionContext::executeFunctions
0 -0.0% -250.2% -947455 100.0% HPHP::ExecutionContext::invokeFunc
Tired of plugging the leaks (pun intended!) I decided to configure our box to be more tolerant of such issues and that’s what I wanted to share today.
First, I disabled HHVM via systemd and substituted in supervisord. Next, I made it run 5 instances concurrently on separate ports:
[program:hhvm_9010]
command=hhvm --config /etc/hhvm/php.ini --config /etc/hhvm/server.ini --user www-data --mode server -vPidFile=/var/run/hhvm/pid_9010 -p 9010 -d hhvm.admin_server.port=9011
directory=/etc/hhvm
autostart=true
autorestart=true
startretries=3
stderr_logfile=/var/log/hhvm/stderr.log
stdout_logfile=/var/log/hhvm/stdout.log
This gave us:
# supervisorctl status
hhvm_9010 RUNNING pid 14800, uptime 9:53:37
hhvm_9020 RUNNING pid 14784, uptime 9:53:38
hhvm_9030 RUNNING pid 14780, uptime 9:53:38
hhvm_9040 RUNNING pid 17395, uptime 0:26:00
hhvm_9050 RUNNING pid 14783, uptime 9:53:38
Coupled with some nginx load balancing, that gave us an instant noticeable boost in stability.
upstream hhvm {
server 127.0.0.1:9010;
server 127.0.0.1:9020;
server 127.0.0.1:9030;
server 127.0.0.1:9040;
server 127.0.0.1:9050;
}
With my fast approaching Europe trip, I didn’t want to be tethered to my terminal and wanted it to detect failure automatically. nginx does provide health_check in its commercial builds, but at this time I’m not too inclined to pay $1500/server/year for the pleasure. Thus, I needed to ping these with minimal effort. I decided to go directly to the fcgi process rather than use nginx to avoid needing to work around the load balancing, and remove the web server as a potential false positive.
I considered learning the fcgi spec but decided to cheat instead. tcpdump to the rescue!
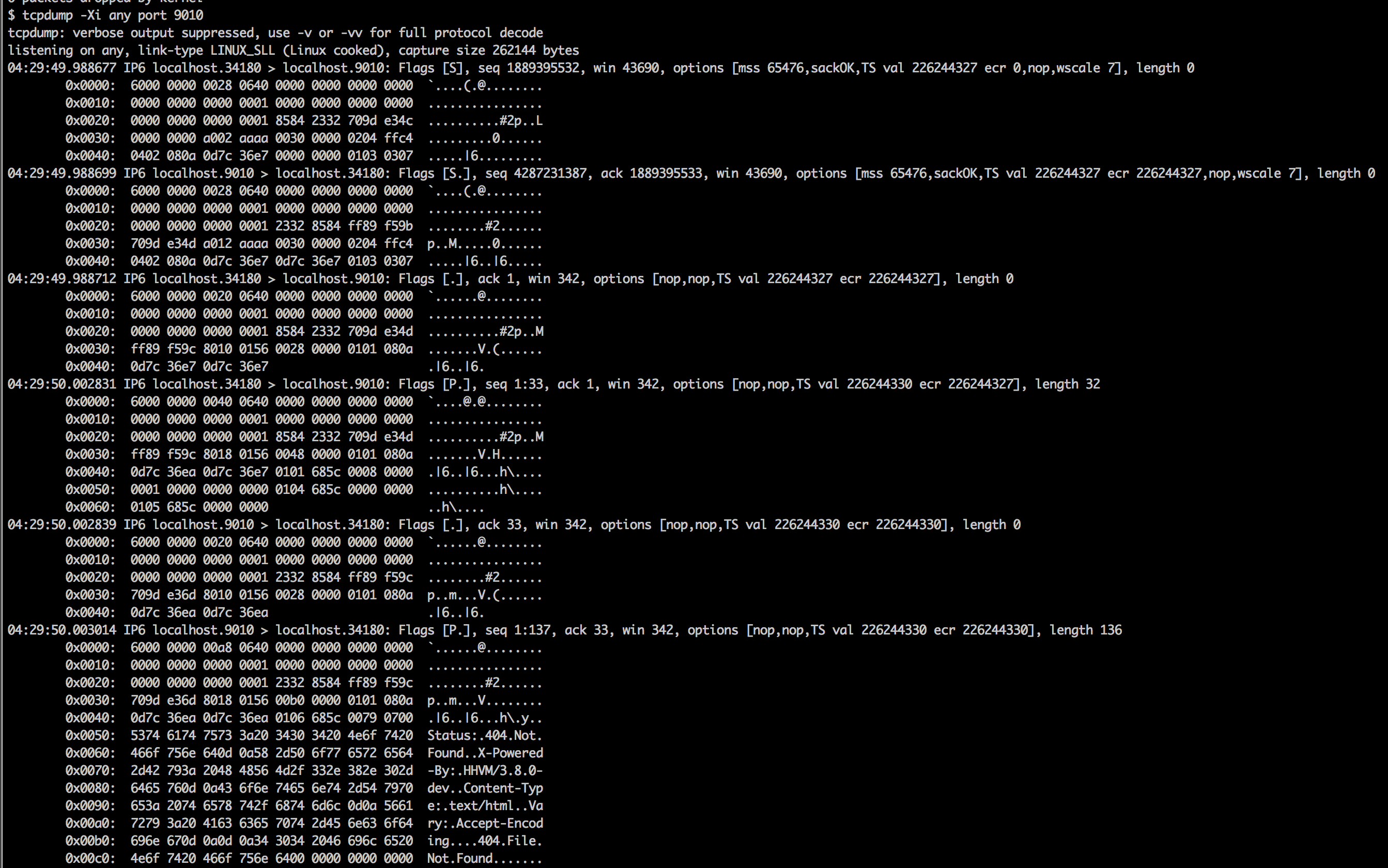
We only really care about the 32 bytes of data used in the first request (indented for emphasis), which cleaned up a little look just like this:
0101 685c 0008 0000 0001 0000 0000 0000 0104 685c 0000 0000 0105 685c 0000 0000
Then to nc, the swiss army knife of networking

Sweet! That was easy!
Next, all that was needed was to iterate the HHVM instances and restart any duds.
#!/bin/bash
readonly PAYLOAD='0101 685c 0008 0000 0001 0000 0000 0000 0104 685c 0000 0000 0105 685c 0000 0000'
readonly HOST=127.0.0.1
supervisorctl status | awk '{print $1 " " $4 " " $6}' | tr -d ',' |
while read NAME PID UPTIME; do
PORT=${NAME##*_}
MATCHES=$(echo $PAYLOAD | tr -d ' ' | xxd -r -p | nc -w 3 $HOST $PORT | grep 'X-Powered-By: HHVM' | wc -l)
if [ $MATCHES -ne 1 ]
then
logger -s "$NAME is not functioning as expected, restarting..."
supervisorctl restart $NAME
fi
done
Since implementation, we’ve had no observed instability and can sleep a little easier. Next, we will likely implement ngx.location.capture_multi on our read requests so that one HHVM node can fail without any end-user impact.
I’m incredibly grateful for the work the HHVM team has put in, and fully intend to stick with it despite the bumps. Hats off to all those involved and the incredibly active community!